데이타베이스의 대용량 테이블을 쿼리문으로 실행할 때 INDEX 정의는 필수 입니다.
특히나 SAP에서 스탠다드 테이블 중에는 엄청나게 큰 테이블들이 많이 존재합니다.
이런 테이블을 ABAP에서 SELECT 쿼리를 사용하여 데이터를 가져올 때 INDEX를 통하여 가져오지 않으면 실행 시간이 무한정 길어지게 됩니다.
테이블 생성할 때 만들어진 KEY 만으로는 모든 쿼리문을 대처할 수 없습니다.
따라서 SELECT 쿼리문에 적용할 수 있는 적절한 인덱스를 만들어 사용할 때가 많아지게 됩니다.
이번 글에서는 SAP ABAP에서 인덱스(Index)의 정의 및 쿼리문에서 인덱스가 적용되지 않는 원인에 대해 알아보겠습니다.
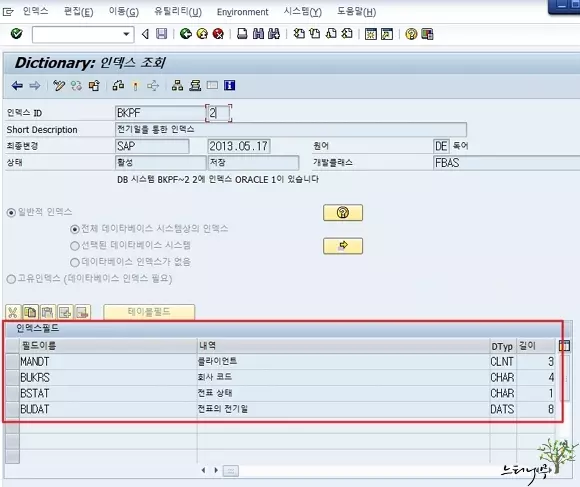
SAP ABAP의 인덱스(Index) 정의
▶ ABAP Dictionary 테이블 인덱스(INDEX)의 정의에 대해 간략하게 정리해 보았습니다.
- INDEX는 Key라는 개념보다 Optimizer가 최적의 처리 경로를 결정하기 위해 사용되는 요소를 말합니다.
- Table의 데이터 접근을 빠르게 하기 위해서 Table과 별개의 물리적인 저장 공간에 Index를 생성해 놓게 됩니다.
- INDEX가 만들어지면 Index를 구성하는 컬럼과 그에 해당하는 Rowid를 가지고 있어 원하는 데이터를 바로 검색할 수 있게 됩니다.(빠른 검색이 인덱스를 만드는 목적이기도 합니다.)
- 자주 실행되는 Database Access(Select)에는 인덱스가 지정되어 있어야 합니다.
- 변경(Insert, Update, Delete)이 많은 테이블에는 인덱스가 너무 많으면 좋지 않습니다. 인덱스에 정의된 칼럼이 많을수록 변경시에 해당 인덱스를 같이 업데이트하게 되므로 DB 성능에 영향을 줄 가능성이 높아집니다. 즉, Insert, Update, Delete 할 때마다 Index도 같이 조정을 해야 하므로 시스템에 더 많은 부하를 주게 됩니다.
- MANDT는 인덱스를 만들 때도 첫 번째 컬럼으로 지정해 주어야 합니다.
ABAP SELECT 문에서 인덱스가 적용되지 않는 쿼리문의 예시
인덱스를 만들어 놓는다고해서 모든 쿼리문이 해당 인덱스를 사용하여 실행되지는 않습니다.
아래의 예제는 인덱스로 정의된 컬럼을 사용했음에도 인덱스가 적용되지 않는 예 입니다.
– INDEX Column이 변형된 경우
SELECT * FROM table WHERE SUBSTR(name, 1, 3) = ‘KIM’
– NOT Operator를 사용한 경우
SELECT * FROM table WHERE name <> ‘KIM’
– NULL, NOT NULL을 사용한 경우
SELECT * FROM table WHERE name IS NOT NULL
– Optimizer의 취사선택을 요구하는 경우
SELECT * FROM table WHERE name LIKE ‘KI%’ AND no = ‘1234’
※ 위에 있는 구문의 결과를 처리하기 위해서는 조건문이 조금 길어지더라도 대체할 수 있는 구문을 사용할 수 있는 방법을 생각해 봅니다.
마무리
이상으로 SAP ABAP에서 인덱스(Index)의 정의 및 쿼리 문에서 올바른 인덱스 적용 방법에 대해 알아보았습니다.
데이터베이스 테이블 사용에 있어 인덱스는 무척 중요한 요소입니다.
테이블의 데이터를 가져올 때 정말 다양한 검색 조건으로 가져오게 됩니다. 적절한 인덱스가 정의 되어져 있다면 좀 더 빠르게 데이터를 가져오고 처리할 수 있습니다.
하지만 무엇이든지 과한 것은 문제가 발생합니다. 인덱스도 마찬가지로 무분별하게 인덱스를 생성해서 사용하게 되면 데이터베이스 전반적인 퍼포먼스에 오히려 악 영향을 줄 수 있습니다.
※ 함께 읽으면 도움이 될 만한 다른 포스팅 글입니다.
이 글이 도움이 되었기를 바랍니다. ^-^